What is a Data Lakehouse?
Table Of Content
Learn about barriers to AI adoptions, particularly lack of AI governance and risk management solutions.
Data Lakehouse
Consistency is when data is in a consistent state when a transaction starts and when it ends. Isolation refers to the intermediate state of transaction being invisible to other transactions. Durability is after a transaction successfully completes, changes to data persist and are not undone, even in the event of a system failure.
Why do you need an Azure data lake?
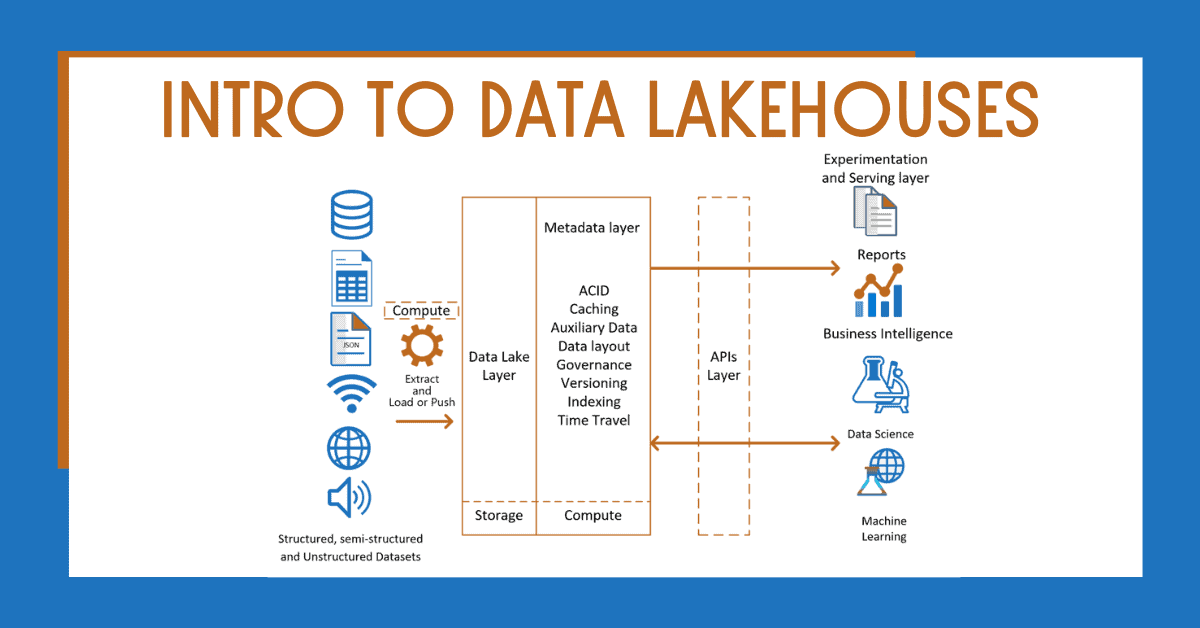
Next, a small segment of the critical business data is ETLd once again to be loaded into the data warehouse for business intelligence and data analytics. It’s a unified catalog that delivers metadata for every object in the lake storage, helping organize and provide information about the data in the system. This layer also gives user the opportunity to use management features such as ACID transactions, file caching, and indexing for faster query.
What is the difference between an Azure data lake and an Azure data warehouse?
Learn about the fast and flexible open-source query engine available with watsonx.data’s open data lakehouse architecture. A data lakehouse uses APIs, to increase task processing and conduct more advanced analytics. Specifically, this layer gives consumers and/or developers the opportunity to use a range of languages and libraries, such as TensorFlow, on an abstract level. In this layer, the structured, unstructured, and semi-structured data is stored in open-source file formats, such as such as Parquet or Optimized Row Columnar (ORC). The real benefit of a lakehouse is the system’s ability to accept all data types at an affordable cost.
Common Two-Tier Data Architecture
IBM Research proposes that the unified approach of data lakehouses creates a unique opportunity for unified data resiliency management. Managed Delta Lake in Azure Databricks provides a layer of reliability that enables you to curate, analyze and derive value from your data lake on the cloud. ACID stands for atomicity, consistency, isolation, and durability; all of which are key properties that define a transaction to ensure data integrity. Atomicity can be defined as all changes to data are performed as if they are a single operation.
The model's performance was evaluated in a validation set of 130 patients from another center. In the training set, multivariate Cox regression analysis revealed that age, WGO type, basic etiology, total bilirubin, creatinine, prothrombin activity, and hepatic encephalopathy stage were all independent prognostic factors in ACLF. We designed a dynamic trend score table based on the changing trends of these indicators. Furthermore, a logistic prediction model (DP-ACLF) was constructed by combining the sum of dynamic trend scores and baseline prognostic parameters. All prognostic scores were calculated based on the clinical data of patients at the third day, first week, and second week after admission, respectively, and were correlated with the 90-day prognosis by ROC analysis.
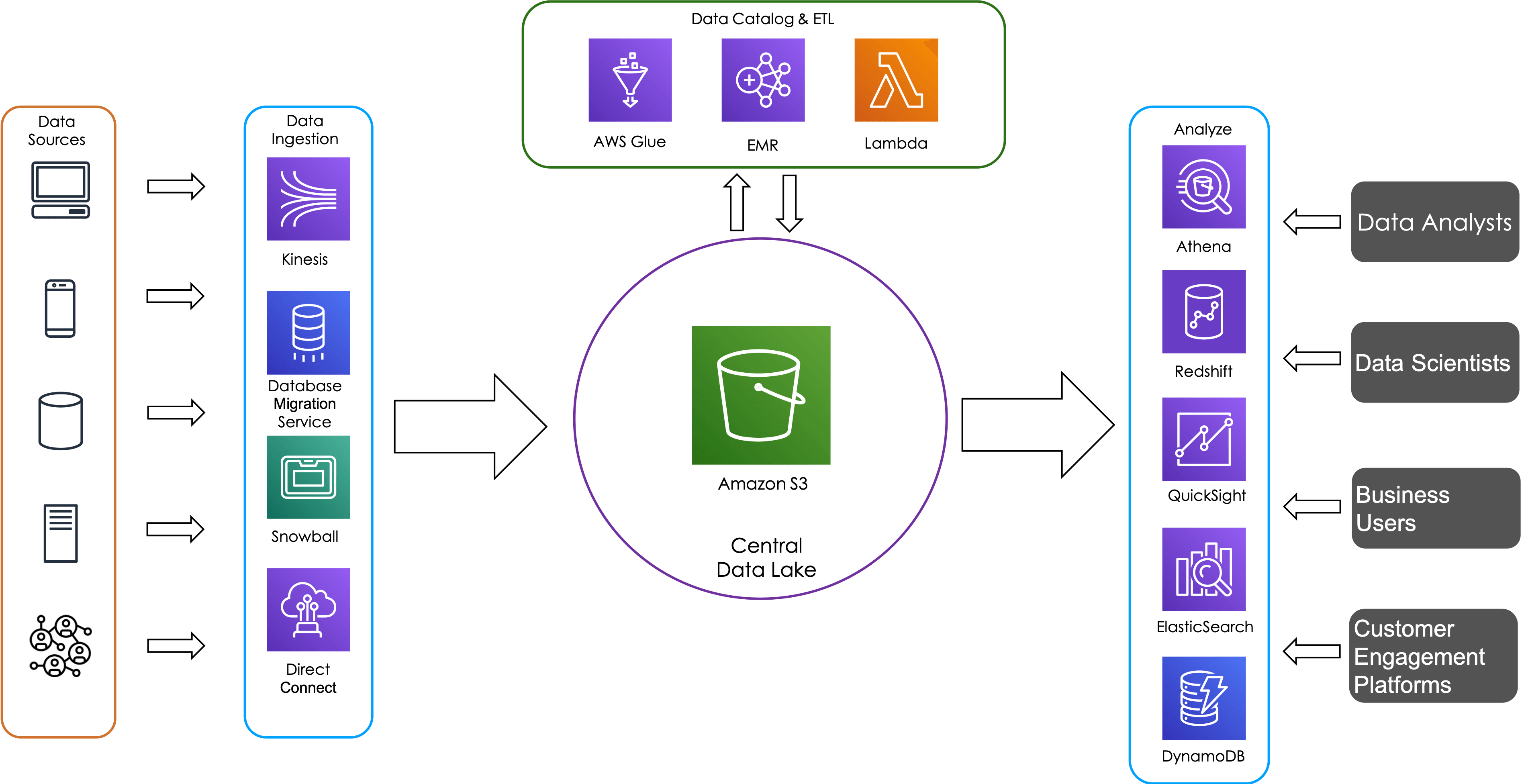
What is an Azure data lake?
Users can implement predefined schemas within this layer, which enable data governance and auditing capabilities. A modern lakehouse architecture that combines the performance, reliability and data integrity of a warehouse with the flexibility, scale and support for unstructured data available in a data lake. This final layer of the data lakehouse architecture hosts client apps and tools, meaning it has access to all metadata and data stored in the lake. Users across an organization can make use of the lakehouse and carry out analytical tasks such as business intelligence dashboards, data visualization, and other machine learning jobs. Modern data lakes leverage cloud elasticity to store virtually unlimited amounts of data "as is," without the need to impose a schema or structure.
Data Lakehouse: Simplicity, Flexibility, and Low Cost
However, coordinating these systems to provide reliable data can be costly in both time and resources. Long processing times contribute to data staleness and additional layers of ETL introduce more risk to data quality. Acute-on-chronic liver failure (ACLF) is a dynamic syndrome, and sequential assessments can reflect its prognosis more accurately. Our aim was to build and validate a new scoring system to predict short-term prognosis using baseline and dynamic data in ACLF. We conducted a retrospective cohort analysis of patients with ACLF from three different hospitals in China. To construct the model, we analyzed a training set of 541 patients from two hospitals.
Other Literature Sources
Databricks injects array of AI tools into Lakehouse - ITPro
Databricks injects array of AI tools into Lakehouse.
Posted: Wed, 28 Jun 2023 07:00:00 GMT [source]
"In recent years, Hedong has focused on improving the quality and efficiency of development, and optimizing the urban spatial structure." said Han Qiming, head of the district's commerce department. The district has taken advantage of the opportunities brought by the regional coordinated development of Beijing-Tianjin-Hebei. In the first half of the year, the district has introduced 202 projects from Beijing and Hebei based enterprises, with an investment totaling 5.58 billion yuan($862.35 million). We know that many of you worry about the environmental impact of travel and are looking for ways of expanding horizons in ways that do minimal harm - and may even bring benefits.
A data lakehouse is a data platform, which merges the best aspects of data warehouses and data lakes into one data management solution. Data warehouses tend to be more performant than data lakes, but they can be more expensive and limited in their ability to scale. A data lakehouse attempts to solve for this by leveraging cloud object storage to store a broader range of data types—that is, structured data, unstructured data and semi-structured data. As previously noted, data lakehouses combine the best features within data warehousing with the most optimal ones within data lakes.
A data lake is a central location that holds a large amount of data in its native, raw format, as well as a way to organize large volumes of highly diverse data. Compared to a hierarchical data warehouse, which stores data in files or folders, a data lake uses a flat architecture to store the data. As a result, you can store raw data in the lake in case it will be needed at a future date — without worrying about the data format, size or storage capacity. Data lakes act as a catch-all system for new data, and data warehouses apply downstream structure to specific data from this system.
Structured Query Language (SQL) is a powerful querying language to explore your data and discover valuable insights. Delta Lake is an open source storage layer that brings reliability to data lakes with ACID transactions, scalable metadata handling and unified streaming and batch data processing. Delta Lake is fully compatible and brings reliability to your existing data lake.



Comments
Post a Comment